
모두야
CH5) 순환 신경망(RNN) -(2) 본문
RNN 구현하기


한 단계의 작업을 수행하는 계층을 RNN 계층, T개 단계의 작업을 한번에 처리하는 계층을 Time RNN 계층이라 한다.
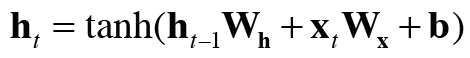



# RNN 구현하기
class RNN:
# 클래스 초기화
def __init__(self, Wx, Wh, b): # 가중치2개, 편향1개
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)] #기울기 초기화
self.cache = None #역전파시 중간 데이터 담을 cache 초기화
#순전파 - 입력2개
def forward(self, x, h_prev): #아래입력x, 왼쪽입력h_prev
Wx, Wh, b = self.params
t = np.dot(h_prev, Wh) + np.dot(x, Wx) + b # 식
h_next = np.tanh(t)
self.cache = (x, h_prev, h_next) #이전 입력h_prev, 출력된(다음입력)h_next
return h_next
#역전파
def backward(self, dh_next): #이전 dh_next
Wx, Wh, b = self.params
x, h_prev, h_next = self.cache
dt = dh_next * (1 - h_next ** 2)
db = np.sum(dt, axis=0)
dWh = np.dot(h_prev.T, dt)
dh_prev = np.dot(dt, Wh.T)
dWx = np.dot(x.T, dt)
dx = np.dot(dt, Wx.T)
self.grads[0][...] = dWx
self.grads[1][...] = dWh
self.grads[2][...] = db
return dx, dh_prevTime RNN 구현하기
Time RNN은 RNN 계층 T개를 연결한 신경망이다.
RNN 계층의 은닉상태 h를 인스턴스 변수로 유지한다.

class TimeRNN:
# 초기화 메서드
def __init__(self, Wx, Wh, b, stateful=False): #가중치,편향,은닉상태 인계여부(실제에서는 True)
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.layers = None #다수의 RNN 계층을 리스트로 저장
self.h, self.dh = None, None #h:마지막 RNN 계층의 은닉상태 저장
#dh : 역전파에서 하나 앞 블록의 은닉상태 기울기 저장
self.stateful = stateful #은닉상태 유지 True
#stateful=True : Time RNN계층이 은닉 상태를 유지한다.->아무리 긴 시계열 데이터라도 Time RNN계층의 순전파를 끊지 않고 전파한다.
#stateful=False: Time RNN 계층은 은닉 상태를 '영행렬'로 초기화한다.상태가 없다.
#순전파
def forward(self, xs): #아래 입력 Xs : T개의 분량 시계열 데이터를 하나로 모은것
Wx, Wh, b = self.params
N, T, D = xs.shape # xs.shape=(N,T,D)=(미니배치크기,T개분량시계열데이터,입력벡터차원수)
D, H = Wx.shape
self.layers = []
hs = np.empty((N, T, H), dtype='f') # 출력값을 담은 hs
if not self.stateful or self.h is None:
self.h = np.zeros((N, H), dtype='f')
# 총 T회 반복되는 RNN 계층 생성
for t in range(T):
layer = RNN(*self.params)
self.h = layer.forward(xs[:, t, :], self.h)
hs[:, t, :] = self.h
self.layers.append(layer) #layer에 추가
return hs
#역전파
def backward(self, dhs):
Wx, Wh, b = self.params
N, T, H = dhs.shape
D, H = Wx.shape
dxs = np.empty((N, T, D), dtype='f')
dh = 0
grads = [0, 0, 0]
for t in reversed(range(T)):
layer = self.layers[t]
dx, dh = layer.backward(dhs[:, t, :] + dh)
dxs[:, t, :] = dx
for i, grad in enumerate(layer.grads):
grads[i] += grad
for i, grad in enumerate(grads):
self.grads[i][...] = grad
self.dh = dh
return dxs
def set_state(self, h):
self.h = h
def reset_state(self):
self.h = NoneRNNLM(RNN Language Model : RNN을 사용한 언어모델)

Embedding 계층 : 단어 ID를 단어의 분산 표현(단어벡터)로 변환한다.
RNN 계층 : 단어의 분산 표현이 RNN 계층으로 입력된다.
: 은닉 상태를 다음 층, 다음 시각의 RNN 계층으로 출력한다.
Affine / Softmax 계층 : 출력 결과를 나타낸다. (확률)

- RNN 계층이 과거에서 현재로 데이터를 계속 흘려보내줌으로써, 과거의 정보를 인코딩하여 저장(기억) 할 수 있다.
- RNN은 "you say"라는 과거 정보를 응집된 은닉 상태 벡터로 저장하고 있다.
RNNLM 구현하는 신경망 - SimpleRnnlm

# coding: utf-8
import sys
sys.path.append('..')
import numpy as np
from common.time_layers import *
class SimpleRnnlm:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
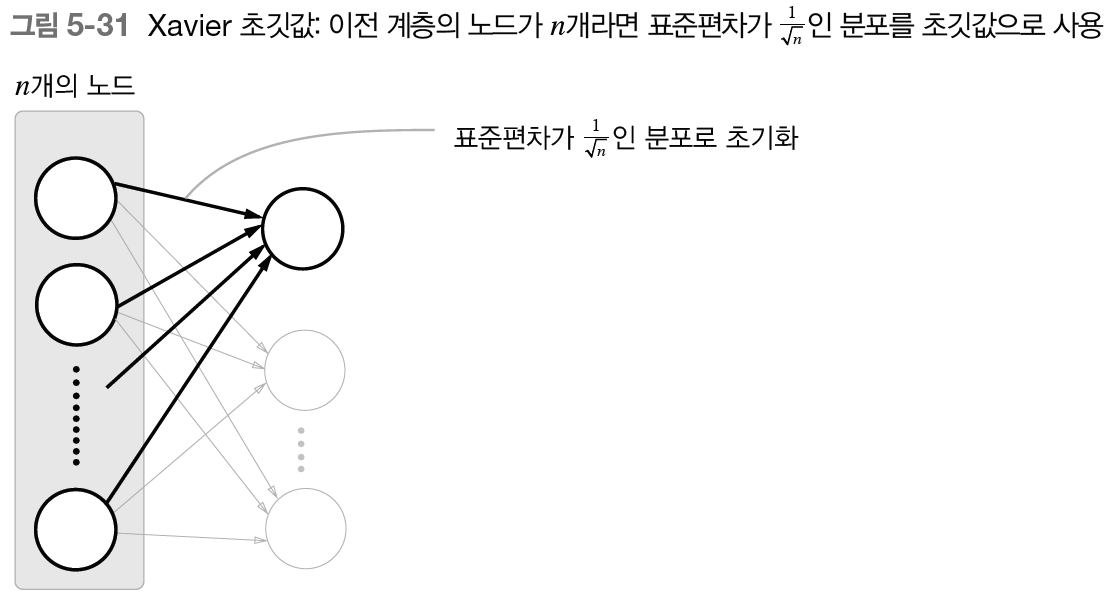
# 가중치 초기화 - Xavier초깃값
embed_W = (rn(V, D) / 100).astype('f')
rnn_Wx = (rn(D, H) / np.sqrt(D)).astype('f')
rnn_Wh = (rn(H, H) / np.sqrt(H)).astype('f')
rnn_b = np.zeros(H).astype('f')
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
# 계층 생성
self.layers = [
TimeEmbedding(embed_W),
TimeRNN(rnn_Wx, rnn_Wh, rnn_b, stateful=True), #stateful=True(이전시각 은닉상태 계승)
TimeAffine(affine_W, affine_b)
]
self.loss_layer = TimeSoftmaxWithLoss()
self.rnn_layer = self.layers[1]
# 모든 가중치와 기울기를 리스트에 모은다.
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
# 순전파
def forward(self, xs, ts):
for layer in self.layers:
xs = layer.forward(xs)
loss = self.loss_layer.forward(xs, ts)
return loss
# 역전파
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
# 신경망 상태 초기화
def reset_state(self):
self.rnn_layer.reset_state()언어 모델 평가 (퍼플렉서티)
언어 모델 : 과거 단어(정보)로 부터 다음에 출현할 단어의 확률 분포를 출력한다.
퍼플렉서티 (perplexity : 혼란도) - 언어 모델의 예측 성능을 평가하는 척도 = 확률의 역수
=> 퍼플렉서티가 작을수록 좋다.
분기 수(number of branches) - 다음에 출현할 수 있는 단어의 후보 수

모델 1에서는 say가 0.8확률로 다음에 출연한다고 예측했고, 이때 perplexity는 1/0.8 = 1.25
모델 2에서는 say가 0.2확률로 다음에 출연한다고 예측했고, 이때 perplexity는 1/0.2 = 5
- 퍼플렉시티는 작을 수록 좋다.
- perplexity = 1.25 -> 분기 수 = 다음에 출현할 수 있는 단어의 후보를 1개 정도이다.
- perplexity = 5 -> 분기수 = 다음에 출현할 수 있는 단어의 후보가 5개나 있다.
좋은 모델은 퍼플렉서티 값이 적다 = 정답 단어를 높은 확률로 예측한다. (최솟값음 1.0)
나쁜 모델은 퍼플렉서티 값이 크다 = 낮은 확률로 예측


N : 데이터의 총 개수
tn : 원핫 벡터로 나타낸 정답 레이블
tnk : n개째 데이터의 k번째 값
퍼플렉서티가 작을수록, 분기수가 줄어든다.
분기 수 = 선택사항의 수 = 확률의 역수
# coding: utf-8
import sys
sys.path.append('..')
import matplotlib.pyplot as plt
import numpy as np
from common.optimizer import SGD
from dataset import ptb
#from simple_rnnlm import SimpleRnnlm
# 하이퍼파라미터 설정
batch_size = 10
wordvec_size = 100
hidden_size = 100 # RNN의 은닉 상태 벡터의 원소 수
time_size = 5 # Truncated BPTT가 한 번에 펼치는 시간 크기
lr = 0.1
max_epoch = 100
# 학습 데이터 읽기(전체 중 1000개만)
corpus, word_to_id, id_to_word = ptb.load_data('train')
corpus_size = 1000
corpus = corpus[:corpus_size]
vocab_size = int(max(corpus) + 1)
xs = corpus[:-1] # 입력
ts = corpus[1:] # 출력(정답 레이블)
data_size = len(xs)
print('말뭉치 크기: %d, 어휘 수: %d' % (corpus_size, vocab_size))
# 학습 시 사용하는 변수
max_iters = data_size // (batch_size * time_size)
time_idx = 0
total_loss = 0
loss_count = 0
ppl_list = []
# 모델 생성
model = SimpleRnnlm(vocab_size, wordvec_size, hidden_size)
optimizer = SGD(lr)
# Truncated BPTT 방식으로 학습
# 미니배치의 각 샘플의 읽기 시작 위치를 계산 - offset에 저장
jump = (corpus_size - 1) // batch_size
offsets = [i * jump for i in range(batch_size)] # 데이터를 읽는 시작 위치 저장
for epoch in range(max_epoch):
for iter in range(max_iters):
# 미니배치 취득 - 데이터 순차적으로 읽기
batch_x = np.empty((batch_size, time_size), dtype='i')
batch_t = np.empty((batch_size, time_size), dtype='i')
for t in range(time_size):
for i, offset in enumerate(offsets):
batch_x[i, t] = xs[(offset + time_idx) % data_size]
batch_t[i, t] = ts[(offset + time_idx) % data_size]
time_idx += 1 #위치
# 기울기를 구하여 매개변수 갱신
loss = model.forward(batch_x, batch_t)
model.backward()
optimizer.update(model.params, model.grads)
total_loss += loss
loss_count += 1
# 에폭마다 퍼플렉서티 평가
ppl = np.exp(total_loss / loss_count) #에폭마다 손실의 평균
print('| 에폭 %d | 퍼플렉서티 %.2f'
% (epoch+1, ppl))
ppl_list.append(float(ppl))
total_loss, loss_count = 0, 0
# 그래프 그리기
x = np.arange(len(ppl_list))
plt.plot(x, ppl_list, label='train')
plt.xlabel('epochs')
plt.ylabel('perplexity')
plt.show()
# coding: utf-8
import sys
sys.path.append('..')
from common.optimizer import SGD
from common.trainer import RnnlmTrainer
from dataset import ptb
#from simple_rnnlm import SimpleRnnlm
# 하이퍼파라미터 설정
batch_size = 10
wordvec_size = 100
hidden_size = 100 # RNN의 은닉 상태 벡터의 원소 수
time_size = 5 # RNN을 펼치는 크기
lr = 0.1
max_epoch = 100
# 학습 데이터 읽기
corpus, word_to_id, id_to_word = ptb.load_data('train')
corpus_size = 1000 # 테스트 데이터셋을 작게 설정
corpus = corpus[:corpus_size]
vocab_size = int(max(corpus) + 1)
xs = corpus[:-1] # 입력
ts = corpus[1:] # 출력(정답 레이블)
# 모델 생성
# model과 optimizer 초기화
model = SimpleRnnlm(vocab_size, wordvec_size, hidden_size)
optimizer = SGD(lr)
trainer = RnnlmTrainer(model, optimizer)
#fit:미니배치 만들고->모델 순/역전파 호출->옵티마이저로 가중치 갱신->퍼플렉서티 구하기
trainer.fit(xs, ts, max_epoch, batch_size, time_size)
trainer.plot()순환 신경망 (RNN)
- 데이터를 순환시키며 과거-현재-미래로 데이터를 계속 흘려보낸다.
- RNN 계층 내부에서 은닉상태가 있다.
- RNN을 이용한 언어모델 : [언어모델; 단어 시퀸스에 확률을 부여하며 다음에 출현할 단어의 확률을 계산한다.]
- 아무리 긴 시계열 데이터라도, RNN의 은닉 상태에 기억된다.
'밑.시.딥 > 2권' 카테고리의 다른 글
| CH6) 게이트가 추가된 RNN (기울기 문제점 대책) (0) | 2021.09.26 |
|---|---|
| CH6) 게이트가 추가된 RNN(기울기 폭발/ 기울기 손실) (0) | 2021.09.26 |
| CH5) 순환 신경망(RNN) -(1) (0) | 2021.09.23 |
| CH4) word2vec 속도 개선 (0) | 2021.09.20 |
| CH3) word2vec - (2) (0) | 2021.09.20 |



