
모두야
CH4) word2vec 속도 개선 본문
앞 장에서 살펴본 CBOW 모델의 문제점은 말뭉치에 포함된 어휘 수가 많아지면 계산량이 커진다는 점이다.
문제점
- 입력층의 원핫 표현과 가중치 행렬 Win의 곱 계산
- 어휘 수가 많아지면 원핫 표현의 벡터 크기도 커진다. - 은닉층과 가중치 행렬 Wout의 곱 및 Softmax 계층의 계산
- Wout 행렬 곱 계산량도 많다.
- 어휘량이 많으면 Softmax 계층에서 계산량이 증가한다.
해결책
- Embedding 새로운 계층 도입
- 네거티브 샘플링 새로운 손실 함수 도입
1. Embedding 계층
기존의 문제점
입력 원핫 벡터를 Matmul 계층에서 가중치 행렬과 곱해 은닉층을 만들어 주었다.
이때 나타나는 결과는 입력(원핫벡터1)이므로 단순히 행렬의 특정 행을 추출하는 것 뿐이다.
따라서 거대한 벡터를 모두 다 곱해줄 필요가 없다.
=> 단어 ID에 해당하는 벡터를 추출하는 계층을 만들자 [Embedding 계층]
단어 임베딩(분산 표현)을 저장한다.
가중치 W로부터 여러 행을 한꺼번에 추출하는 방법

- 원하는 행 번호들을 배열에 명시하면 됨
- 순전파
- 가중치W의 특정 행을 추출
- 특정 행 뉴런만 다음 층으로 흘려 보낸다.
- 역전파
- 앞 층으로부터 전해진 기울기를 다음 층으로 흘려 보낸다.
- 가중치 dW의 특정행(idx)에 설정한다.
- 갱신하려는 행 번호(idx)와 그 기울기(dout)을 따로 저장하면, 가중치(W)의 특정 행만 갱신할 수 있다.
class Embedding:
def __init__(self,W):
self.params=[W]
self.grads=[np.zeros_like(W)]
self.idx = None # 추출하는 행의 인덱스를 배열로 저장
def forward(self,idx):
W, = self.params
self.idx = idx
out = W[idx]
return out
def backward(self,dout):
dW, = self.grads # 가중치 dW를 꺼낸 후
dW[...] = 0 # dW의 형상을 유지하면 원소를 0으로 덮는다
for i,word_id in enumerate(self.idx): #인덱스에 기울기를 더했다 - idx에 중복 인덱스가 있더라도 처리 됨
dW[word_id] += dout[i]
# 혹은
# np.add.at(dW,self.idx,dout) # dout을 dW의 idx번째 행에 더해준다
return None2. 네거티브 샘플링
행렬곱과 softmax 계층 계산
- 어휘가 많아져도 계산량이 적어진다. 은닉층 이후 계산이 오래 걸리는 곳
- 은닉층의 뉴런과 가중치 행렬(Wout)의 곱
- Softmax 계층의 계산
이중 분류로 바꾸기
다중 분류 문제를 이중 분류 문제로 근사시킨다.
Q1. (다중분류) 맥락이 you와 goodbye 일 때, 타깃 단어는 무엇 입니까?
Q2. (이중분류) 맥락이 you와 goodbye 일 때, 타깃 단어는 say 입니까? - 높은 확률을 띄는 단어


Embedding 계층을 통해 은닉층에 1개의 행을 전달 받았다. h = (1,100)
은닉층의 출력과 타겟으로 예상되는 가중치가 높은 행을 내적하여 출력층 s는 (1,1)이 된다.
| 다중 분류 | 이진 분류 | |
| 출력층(점수를 확률로 변환) | 소프트맥스 | 시그모이드 함수 |
| 손실 함수 | 교차 엔트로피 오차 | 교차 엔트로피 오차 |


소프트맥스 함수를 이용하면
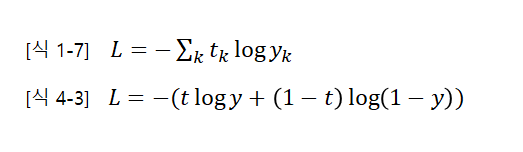
이중분류 교차 엔트로피 [식4.3] : y는 시그모이드 함수의 출력, t는 정답 레이블
: t=1 이면 정답, t=0이면 오답


# Embedding Dot 계층
class EmbeddingDot:
def __init__(self, W):
self.embed = Embedding(W) # embedding 계층
self.params = self.embed.params
self.grads = self.embed.grads # 기울기
self.cache = None # 순전파 시 계산 결과 유지
# 순전파
def forward(self, h, idx): # 은닉층 뉴런h, 단어ID 배열 idx(미니배치)
target_W = self.embed.forward(idx) # 이전 idx 받아옴
out = np.sum(target_W * h, axis=1) # 내적 계산
self.cache = (h, target_W)
return out
# 역전파
def backward(self, dout):
h, target_W = self.cache
dout = dout.reshape(dout.shape[0], 1)
dtarget_W = dout * h
self.embed.backward(dtarget_W)
dh = dout * target_W
return dh네거티프 샘플링
다중분류를 이진분류로 다루려면 정답과 오답에 대해 각각 분류할 수 있어야한다.
이전까지 say입니까? 라는 대답에 yes일 경우만 살펴보았다. 오답일 경우에 대해서도 학습 시켜야한다.
부정적인 단어(정답 say가 아닌경우)에 대해 학습 시키려면 너무 많다. 몇가지 부정적 예를 샘플링 하여 학습시킨다.
네거티브 샘플링 : 긍적적 예의 손실과 몇 개의 샘플링 된 부정적 예의 손실을 더하여 최종 손실을 구한다.

부정적 예는 어떻게 샘플링 할까?
- 말뭉치의 통계 데이터를 기초로 샘플링 한다.
- 말뭉치에서 단어 빈도를 기준으로 샘플링 한다.
- 말뭉치에서 각 단어의 출현 횟수를 구해 '확률분포'를 나타낸다.
# 네거티브 샘플링 구현 (p174)
class NegativeSamplingLoss:
def __init__(self, W, corpus, power=0.75, sample_size=5): #가중치,말뭉치(단어ID),확률에 곱할 값power,부정적 샘플링 횟수
self.sample_size = sample_size
self.sampler = UnigramSampler(corpus, power, sample_size) #부정적 샘플링 클래스 가져옴
self.loss_layers = [SigmoidWithLoss() for _ in range(sample_size + 1)] # 샘플 갯수만큼 계층 생성(긍정적 예+ 부정적 예)
self.embed_dot_layers = [EmbeddingDot(W) for _ in range(sample_size + 1)]
self.params, self.grads = [], [] # 0번째가 긍정적, 이후 부정적 샘플을 위한 계층
for layer in self.embed_dot_layers:
self.params += layer.params
self.grads += layer.grads
# 순전파
def forward(self, h, target): #은닉층 뉴런h, 긍정적 예target
batch_size = target.shape[0]
negative_sample = self.sampler.get_negative_sample(target) #부정적 예 샘플링하여 저장
# 긍정적 예 순전파
score = self.embed_dot_layers[0].forward(h, target)
correct_label = np.ones(batch_size, dtype=np.int32)
loss = self.loss_layers[0].forward(score, correct_label)
# 부정적 예 순전파
negative_label = np.zeros(batch_size, dtype=np.int32)
for i in range(self.sample_size):
negative_target = negative_sample[:, i]
score = self.embed_dot_layers[1 + i].forward(h, negative_target)
loss += self.loss_layers[1 + i].forward(score, negative_label)
return loss
def backward(self, dout=1):
dh = 0
for l0, l1 in zip(self.loss_layers, self.embed_dot_layers):
dscore = l0.backward(dout)
dh += l1.backward(dscore)
return dh
'밑.시.딥 > 2권' 카테고리의 다른 글
| CH5) 순환 신경망(RNN) -(2) (0) | 2021.09.24 |
|---|---|
| CH5) 순환 신경망(RNN) -(1) (0) | 2021.09.23 |
| CH3) word2vec - (2) (0) | 2021.09.20 |
| CH3) word2vec - 간단ver (1) (0) | 2021.09.19 |
| CH2) 자연어와 단어의 분산 표현 - (1) (0) | 2021.09.15 |



