
모두야
CH8) 딥러닝 본문
딥러닝 : 층을 깊게 한 심층 신경망이다.
앞에서 나타나느 신경망 뒷단에 층을 하나 추가하면 심층 신경망이 되긴 하지만, 문제가 몇 개 있다.
신경망
신경망을 구성하는 다양한 계층
학습에 효과적인 기술
영상 분야에 유효한 CNN
매개변수 최적화 기법
=> 기술들을 집약하여 심층 신경망을 만들자.

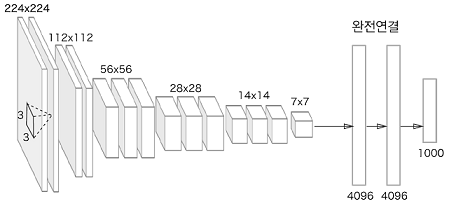
합성곱 Conv 계층 모두 3x3 크기의 작은 필터이다. 층이 깊어지면서 채널 수가 더 늘어난다.
=> 합성곱 계층의 채널수는 16,16,32,32,64,64로 늘어난다. Why?
풀링 계층을 추가하여 중간 데이터의 공간 크기를 점차 줄여간다.
마지막에서 완전연결 계층은 드롭아웃 계층을 사용한다.
가중치 초깃값 He, 가중치 매개변수 갱신 Adam을 이용한다.
신경망의 특징
- 3X3의 작은 필터를 사용한 합성곱 계층
- 활성화 함수는 ReLU
- 완전연결 계층 뒤에 드롭아웃 계층 사용
- Adam을 사용하여 최적화
- 가중치 초깃값은 'He의 초깃값'
정확도 더 높이는 기술
- 앙상블 학습
- 학습률 감소
- 데이터 확장 data agmentation
데이터 확장
입력 이미지에 미세한 변화를 주어 인위적으로 확장시킨다.
- crop - 이미지 일부 잘라냄
- flip - 이미지 좌우/상하 반전
- rotation - 이미지 회전
- scaling - 이미지 확대 축소
- cutout - 이미지 일부를 사각형 모양으로 검은색 칠한다
- cutmix - 두 이미지 합쳐서 학습 시킬때, 이미지가 차지하는 비율만큼 학습
층을 깊게 하는 것이 왜 중요한가
층의 깊이에 비례야하여 정확도가 좋아진다.
장점
신경망의 매개변수 수가 줄어든다.
층을 반복할수록, 층이 깊어질수록 매개변수 수는 적어진다.
=> 넓은 수용 영역을 소화한다.
-> 합성곱 계층 사이에 활성화함수 ReLu를 넣어 신경망의 표현력을 개선시킨다.
학습 효율성도 좋아진다.
층을 깊게하여 학습 데이터 양이 줄고, 학습을 고속으로 수행할 수 있다.
CNN 합성곱 계층이 정보를 계층적으로 추출하고 있다.
합성곱 계층에서는, 에지 등 단순한 패턴에 뉴런이 반응하고 층이 깊어지면서 텍스쳐와 사물의 일부와 같이 점차 복잡한 것에 반응한다.
EX) 개를 인식하는 신경망
얕은 신경망의 경우, 합성곱 계층은 개의 특징 대부분을 한번에 이해하여야 한다.
개의 특징을 알기 위해선, 많은 학습 데이터가 필요하고 학습 시간 또한 오래 걸릴것이다.
깊은 신경망의 경우, 학습해야할 문제를 계층적으로 분해할 수 있다.
처음 층은 에지학습-적은 학습 데이터로 효율적으로 학습한다.
또한, 정보를 계층적으로 전달할 수 있다.
에지를 추출한 층 -> 에지 정보를 사용함 -> 더 고도의 패턴을 효과적으로 학습한다.
8.2 딥러닝의 트렌드
이미지넷
100만 장이 넘는 이미지를 담고 있는 데이터셋
ISLVRC 대회의 '분류'에서는 1,000개의 클래스를 제대로 분류하는지 겨룬다.
2012년 AlexNet을 등장으로 오류율이 급격히 줄었고, 2015년 ResNet은 150층이 넘는 심층 신경망으로 오류율이 가장 낮다.
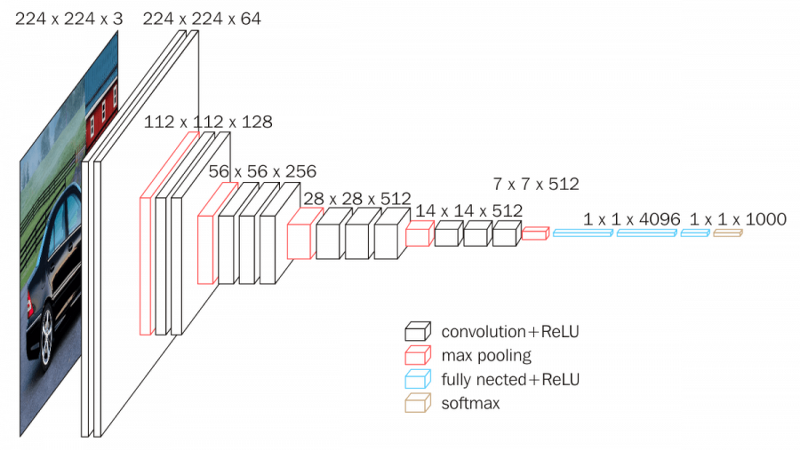
VGG
합성곱 계층과 풀링 계층으로 구성된 기본 CNN 이다.
16층, 19층으로 심화하여 VGG16, VGG19라고 구분한다.
3X3 작은 필터를 사용하여 합성곱 계층을 연속으로 거친다.
풀링 계층으로 크기를 절반으로 줄이는 처리를 반복한다.
마지막에는 완전연결 계층을 통과시켜 결과를 출력한다.
GoogLeNet
세로방향, 가로방향으로도 깊다.
가로 방향은 '폭' = 인셉션 구조
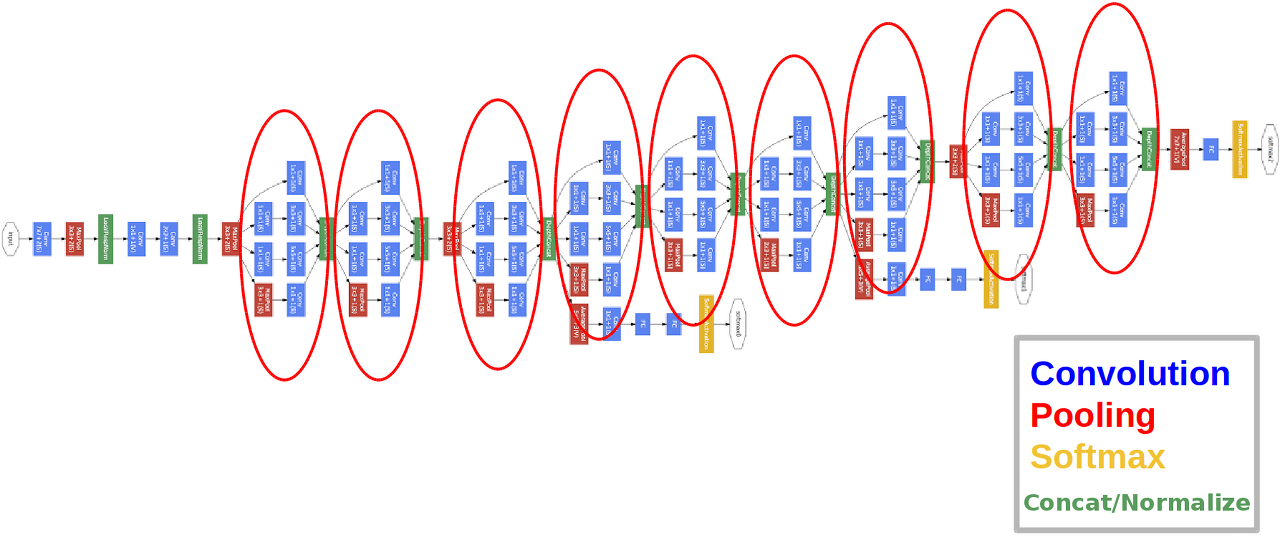
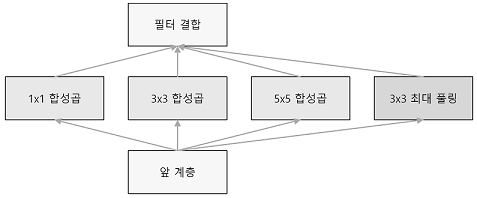
인셉션 구조 : 크기가 다른 필터와 풀링 (여러개를 적용한다) 하여 결과를 결합한다.
GoogLeNet은 1x1 크기의 필터를 사용한 합성곱 계층을 사용한다.
-> 1x1 합성곱 연산은 채널 쪽으로 크기를 줄이는 것이다.
=> 매개변수 제거와 고속 처리에 유용하다.
ResNet ( Residual Network )
마이크로소프트가 개발한 네트워크이다.
지금보다 더 깊은 층을 만드는 특별한 장치가 있다.
딥러닝에서, 층이 지나치게 깊으면 학습이 잘 되지 않고 성능이 떨어지는 경우도 많다.
=> 스킵 연결 skip connection을 도입한다.
==> 층의 깊이에 비례하여 성능을 향상 시킨다.
스킵연결 : 입력 데이터를 합성곱 계층을 건너 뛰어 출력에 바로 더하는 구조이다.
층은 깊어져도, 학습은 효율적으로 할 수 있다.
why? 역전파 때 스킵 연결이 신호 감쇠를 막아준다.
역전파 때 상류의 기울기를 그대로 하류로 보낸다.
기울기가 작아지거나, 커질 걱정이 없다.
=> 층이 깊어지면서 기울기가 작아지는 소실 문제를 줄여준다.
전이 학습 : 학습된 가중치를 다른 신경망에 복사하여 그 상태로 재학습을 수행한다.
예) VGG와 구성이 같은 신경망을 준비하고, 미리 학습된 가중치를 초깃값으로 설정하여 새로운 데이터셋을 대상으로 재학습 (fine tunning) 수행한다.
전이학습은 보유한 데이터셋이 적을 때 유용한 방법이다.
8.3 딥러닝 고속화
CPU로 대량의 연산을 하기 부족하다.
GPU를 통해 고속으로 처리한다.
AlexNet 처리 속도를 살펴볼 때, 합성곱 계층에서의 처리시간이 매우 오래 걸린다.
합성곱 계층은 '단일 곱셈-누산'이다.
GPU 컴퓨팅
병렬 수치 연산을 고속으로 수행하며, 범용 수지 연산을 빠르게 처리한다.
딥러닝은 큰 행렬의 내적의 연속이다. GPU는 대량의 병렬 연산에 빠르다.
=> 엔비디아, AMD
==> 딥러닝에 더 최적화 된 엔비디아 (개발환경은 CUDA), cnDNN은 CUDA 위에서 동작하는 라이브러리로, 딥러닝에 최적화된 함수로 구현되어 있다.
분산 학습
딥러닝 학습을 수평 확장 (분산 학습)하자.
분산 학습을 지원하는 딥러닝 프레임워크 CNTK
'밑.시.딥 > 1권' 카테고리의 다른 글
| CH7) 합성곱 신경망 ( CNN ) - (2) (0) | 2021.07.25 |
|---|---|
| CH7) 합성곱 신경망 ( CNN ) (0) | 2021.07.25 |
| CH6) 학습 관련 기술들 (0) | 2021.07.24 |
| CH5) 오차역전파법 (0) | 2021.07.24 |
| CH4) 신경망 학습 - (2) (0) | 2021.07.23 |



