
모두야
CH3) 신경망 - (2) 본문
CH3) 신경망 - (1)
CH2) 퍼셉트론 이전 글에서 퍼셉트론에 대하여 정리하였다. 좋은 점은 이론상 컴퓨터가 수행하는 복잡한 처리도 퍼셉트론으로 표현이 가능했다. 나쁜 점은 가중치를 설정하는 부분에서는 여전히
meme2.tistory.com
3.4 3층 신경망 구현하기
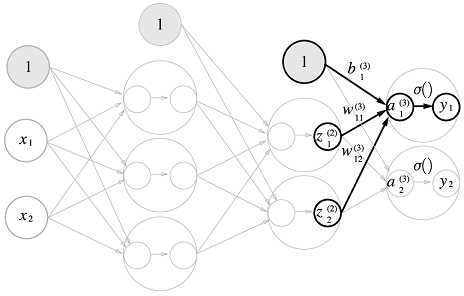
w12 (1) : (1)층 가중치, 2층 1번째 뉴런, 1층 2번째 뉴런
- 구현은 각 층 모두 동일하다.
- 마지막 출력층 단계에서 활성화함수는 다르다. (3.5참고)



def init_network():
network = {} # network의 딕셔너리 형태로 저장
network['W1'] = np.array([[0.1,0.3,0.5],[0.2,0.4,0.6]]) # 가중치1 (입력->1층)
network['b1'] = np.array([0.1,0.2,0.3]) # 편향1(입력->1층)
network['W2'] = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]]) #가중치2 (1층->2층)
network['b2'] = np.array([0.1, 0.2]) #편향2 (1층->2층)
network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]]) #가중치3 (2층->출력층)
network['b3'] = np.array([0.1, 0.2]) #편향2 (2층->출력층)
return network
#신호가 순방향(입력에서 출력 방향)으로 전달됨(순전파)임을 알리기 위함이다.
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = identity_function(a3)
return y
network = init_network()
x = np.array([1.0, 0.5]) #입력
y = forward(network, x) #출력
print(y)
>> [0.31682708 0.69627909]3.5 출력층 설계하기
신경망 -> 분류와 회귀에도 이용할 수 있다. 다만, 출력층에서 둘의 차이가 존재한다.
지도학습
- 입력(특성)과 정답(레이블)이 있다.
분류 : 데이터가 어느 카테고리에 속해 있는가를 찾는다. (강아지/고양이 분류)
회귀 : 데이터의 연속적인 수치를 예측한다. (ex. 날씨에 따른 맥주 판매량 - 내일 온도는 26도인데, 맥주 얼마나 팔릴까 예측)


출력층에서 둘의 차이가 존재한다
Why?
분류(소프트맥스 함수) : 분류는 데이터에 대한 카테고리를 정해야하므로, 확률을 나타내는 소프트맥스 함수가 좋다.
회귀(항등 함수) : 회귀는 값 자체를 예측 해야하므로, 항등함수를 이용한다.

소프트맥스 함수 (분류)
: 한 클래스(카테고리)에 대한 확률이다.
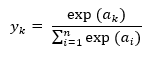
소프트맥스 함수 식


오른쪽 코드처럼 진행하게 되면 소프트맥수 함수 식에는 알맞다.
하지만, 컴퓨터에 그대로 사용하게 될 경우 오버플로우문제가 발생한다.
식에 들어있는 지수함수의 결과로 너무 큰 값이 출력되며, 큰 값끼리 나누게 되면 결과는 불안정해진다.
+) 컴퓨터는 4bytes, 8bytes의 크기로 유한한 데이터를 다룬다. 컴퓨터의 메모리는 한정되어 있으며 표현하기 어려운 큰 숫자는 오버플로우가 발생한다.
특징
- 소프트맥스 함수의 출력은 0.0 ~ 1.0 사이의 실수
- 소프트맥스 함수의 출력의 총합은 1
= 소프트맥스 함수의 출력은 확률이다.
# 소프트맥스 개선 구현
def softmax_2(a):
c = np.max(a)
exp_a = np.exp(a-c) # 오버플로 대책
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
a = np.array([0.3,2.9,4.0])
y = softmax_2(a)
print(y)
>> [0.01821127 0.24519181 0.73659691]
np.sum(y)
>> 1.0y[0] : 1.8% 의 확률로 정답이다.
y[1] : 24.5%의 확률로 정답이다.
y[2] : 73.7% 의 확률로 정답이다.
= 클래스 2가 정답일 확률이 크다. (분류)
하지만 !
분류 출력 과정에서, 이전 신경망 층에서도 출력이 가장 큰 것이 소프트맥스 함수 적용 후에도 가장 클 것이다.
앞에만 봐도 추론이 가능하다는 것이다. 굳이 메모리를 더 쓸 이유는 없지 않은가.
따라서, 추론 과정의 출력층 소프트맥스 함수는 생략하는 것이 일반적이다.
기계학습 풀이
1. 학습 : 모델을 학습 시킨 후
2. 추론 : 앞에서 학습한 모델로 미지의 데이터에 대해 분류한다. - 출력층 소프트맥스 함수 생략
신경망 학습
출력층에서 소프트맥스 함수를 이용한다. (4장 참조)
출력층의 뉴런 수 정하기
분류 - 분류하고 싶은 클래스 수만큼 뉴런수를 설정한다.
ex ) 입력 이미지를 숫자 0~9로 분류하는 문제일 경우, 클래스는 10개 이므로 출력층 뉴런의 갯수는 10개로 설정한다.
정리해보자면,
표현하고자 하는 데이터에 따라 (출력하고자 하는 형식)
- 활성화 함수 - 출력에 알맞은 함수 지정
- 뉴런의 수 - 출력 갯수 만큼 지정 (mnist = 10개)
3.6 손글씨 숫자 분류 (MNIST)
신경망 학습
1. 학습 : 훈련 데이터를 사용해 가중치 매개변수를 학습한다.
2. 추론 (순전파) : 앞서 학습한 매개변수를 사용하여 입력 데이터를 분류한다.
MNIST 데이터셋
- 기계 학습에서 유명한 데이터 셋으로, 손글씨 숫자 이미지 집합이다.
- 0 ~ 9 까지의 숫자 이미지로 구성되어있다.
- 훈련 이미지가 60,000장, 시험 이미지가 10,000장으로 준비 되어있다.
- 28x28 크기의 회색조(1채널) 이미지이다.
- 0 - 255 픽셀 값을 취한다.
# 이미지 가져오기 import sys import os sys.path.append(os.pardir) # 부모 디렉터리 파일 가져옴 from dataset.mnist import load_mnist #dataset/mnist.py의 load_mnist 함수를 가져온다 # load_mnist 함수로 MNIST 데이터셋을 읽어온다. (X_train,y_train),(X_test,y_test) = load_mnist(flatten=True, normalize=False) print(X_train.shape) print(y_train.shape) print(X_test.shape) print(y_test.shape)
load_mnist 함수는 MNIST 데이터를 (훈련 이미지, 훈련 레이블) , (시험 이미지, 시험 레이블) 형식으로 반환한다.
인수로는 normalize, flatten, one_hot_label 세 가지를 설정할 수 있다. 모두 bool 값이다.
1) normalize : 입력 이미지의 픽셀값을 0.0 ~ 1.0 사이의 값으로 정규화할지 정한다.
: False로 설정하면 입력 이미지의 픽셀 원래 값 그대로 0 ~ 255 사이의 값으로 유지된다.
2) flatten : 입력 이미지를 평탄하게 , 즉 1차원 배열로 만들지 정한다.
: False로 설정하면 입력 이미지의 1x28x28의 3차원 배열
: True로 설정하면 784개의 원소로 이뤄진 1차원 배열로 저장한다.
3) one_hot_label : 레이블을 원-핫 인코딩(one-hot encoding) 형태로 저장할지 정한다.
: 원-핫 인코딩이란, [0,0,1,0,0,0,0,0,0,0] 처럼 정답을 뜻하는 원소만 1이고 나머지는 0인 배열이다.
: False 일 경우, 7이나 2와 같이 숫자의 형태의 레이블을 저장하고
: True 일 경우, 레이블을 원-핫 인코딩하여 저장한다.
# 이미지 화면에 띄우기
import sys,os
sys.path.append(os.pardir)
import numpy as np
from dataset.mnist import load_mnist
from PIL import Image
def img_show(img):
pil_img = Image.fromarray(np.uint8(img))
pil_img.show()
(x_train,y_train), (x_test,y_test) = load_mnist(flatten=True,normalize=False)
img = x_train[0]
label = y_train[0]
print(label)
print(img.shape) #784 , flatten=False일 경우 (1,28,28)
img_reshape = img.reshape(28,28)
img_show(img_reshape)이미지 표시 : PIL 모듈을 사용한다.
flatten=True 로 설정하여 이미지는 (784, ) 와 같이 1차원 넘파이 배열로 저장되어 있다.
이미지를 표시하기 위해 28x28 크기로 변형하여야 한다.
reshape( ) 메서드에 원하는 형상을 인수로 지정하여 넘파이 배열 형상을 바꾼다.
넘파이로 저장된 이미지 데이터를 PIL용 데이터 객체로 변환해야하며, 이때 Image.fromarray( )를 사용한다.
신경망 추론 구현
- 입력층 뉴런은 784개 - 이미지 크기가 28x28=784 이기 때문이다.
- 출력층 뉴런은 10개 - 0~9까지 숫자를 구분하는 문제이기 때문이다.
- 은닉층은 2개 - 첫번째 은닉층에서 50개 뉴런, 두번째 은닉층은 100개의 뉴런으로 배치한다. (숫자는 임의)
MNIST 데이터셋을 얻고, 네트워크를 생성한다.
배치 처리
입력 데이터와 가중치 매개변수의 '형상'
To be Continued...
'밑.시.딥 > 1권' 카테고리의 다른 글
| CH4) 신경망 학습 - (2) (0) | 2021.07.23 |
|---|---|
| CH4) 신경망 학습 - (1) (0) | 2021.07.15 |
| CH3) 신경망 - (1) (0) | 2021.07.08 |
| CH2) 퍼셉트론 (0) | 2021.07.08 |
| CH1)헬로 파이썬 (1) | 2021.04.21 |



