
모두야
회귀/분류metric , OneHot인코딩, MDP(마르코프 결정 과정) 본문
머신러닝
회귀 / 분류시 알맞은 metric은 무엇일까요?
-- 회사가 원하는 방향으로 대답할 수 있을듯 (사용하는 모델관련, 최신모델 어필)

회귀 (Regression) - 숫자를 예측하고 싶다면 지도학습의 회귀로 해결한다.
ex ) 판매량 예측, 기온 변화량, 나이에 따른 성장키 예측
분류 (Classification) - 문자/이미지를 예측하고 싶다면 지도학습의 분류로 해결한다.
ex ) 스팸메일 분류, 악성 종양 음성/양성 판단
회귀
" 실제 값 vs 모델이 예측하는 값 " 의 차이를 통해 평가 진행
RSS(단순 오차 제곱 합) : 예측값과 실제값의 오차의 제곱합

MSE(평균 제곱 오차) : RSS를 데이터의 갯수만큼 나눈 값
RMSE : MSE에 루트 씌운 값
: 오차의 제곱이므로, 이상치(Outlier) 잡아내는데 효과적
- 틀린걸 더 많이 틀렸다고 알려준다.

MAE(평균 절대값 오차) : 예측값과 실제값의 오차의 절대값의 평균
RMAE : MAE에 루트 씌운 값
: 변동치가 큰 지표와 낮은 지표를 같이 예측하는데 효과적
== 두가지 모두 평균을 그대로 이용하므로, 데이터 크기에 의존한다는 단점이 있다.
데이터 전체 크기 N에 따라 나뉘는 분모가 달라진다.
▶ 사용하는 metric
▶ R2 (결정계수) 로 해결 : 1에 가까울 수록 높은 성능의 모델이다.
결정계수의 분자인 '오차'는 실제값과 예측값의 차이 인데, 이 값이 0에 가까울 수록 모델의 성능이 좋다는 뜻이다. 따라서 결정계수 R2는 1에 가까워질 수록 좋은 모델이다.
- R2 공식


- 결정계수를 이용하여 회귀 정확도 알아볼 수 있다.

분류
모델이 데이터를 얼마나 알맞은 클래스로 분류 했느냐를 측정하는 혼동행렬(Confusion Matrix) 사용한다.

TP (True Positive)
: 실제 데이터 P → 모델 P 잘 예측 (T)
FN (False Negative)
: 실제 데이터 P → 모델 N 잘못 예측 (F)
FP (False Positive)
: 실제 데이터 N → 모델 P 잘못 예측 (F)
TN (True Negative)
: 실제 데이터 N → 모델 N 잘 예측 (T)
▶ 사용하는 metric

정밀도 (Precision) : '모델이 P라고 분류한 데이터' 중 , '실제 데이터가 P'인 비율
: 음성 N 데이터가 중요하여 놓치지 말아야할 때 사용
ex ) 스팸메일 분류 (스팸 P, 일반 N 일때, 일반메일N이 스팸메일함으로 가면 안된다.)

재현율 (Recall) : ' 실제 데이터 P ' 중, '모델이 P라고 잘 예측한 데이터'의 비율
: 양성 P 데이터가 중요하여 놓치지 말아야할 때 사용
ex ) 암환자 분류 ( 양성 P 암환자가 음성N 정상환자로 분류되면 안된다.)
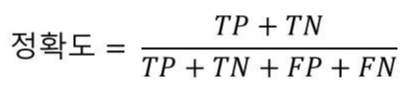
정확도 ( Accuracy ) : 모델이 얼마나 데이터를 잘 분류 했느냐 / 분류 결과가 얼마나 True 인가
FPR (False Positive Rate) : 실제로 N인 데이터 중에서 모델이 P라고 잘못 분류한 데이터의 비율 FP/(FP+TN)

F1 score : precision 과 recall의 조화평균
precision 정밀도와 recall 재현율이 0에 가까울수록 낮게 나타난다.
자연어처리
One Hot 인코딩에 대해 설명해주세요.
- 자연어 처리에서 문자를 숫자로 바꾸는 기법 중 하나이다.
- 데이터를 수많은 0(False)과 한개의 1(True)로 변형하는 인코딩이다. [ 0,0,0,1,0,0,0 ]
- 표현하고 싶은 단어의 인덱스에 1을 부여하고, 나머지 인덱스에는 0으로 표현한다.
과정
1 ) < 토큰화 > 단어 문장 쪼개기
2 ) < 정수 인코딩 > 각 단어에 대한 인덱스 부여
3 ) < 원핫인코딩 > 원하는 단어에 1 (True) , 나머지 단어에 0 (False)으로 나타낸다.
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
str = "원 핫 인코딩에 대해 설명 해주세요."
tokenizer = Tokenizer()
tokenizer.fit_on_texts([str])
word2index = tokenizer.word_index
print(word2index)
# {'원': 1, '핫': 2, '인코딩에': 3, '대해': 4, '설명': 5, '해주세요': 6}def one_hot_encoding(word, word2index):
one_hot_vector = [0]*(len(word2index))
index=word2index[word]
one_hot_vector[index]=1
return one_hot_vector
one_hot_encoding("인코딩에",word2index)
# [0, 0, 0, 1, 0, 0]
장점 : 정답을 한번에 찾을 수 있다.
: 단어의 인덱스 위치만 알 수 있다. 단어의 임베딩으로 연결
단점 : 차원의 저주가 생길 수 있다.
: 원핫벡터를 쓰면 1,0만 쓰므로, 단어의 의미가 없음 / 단어들간의 유사도 알기 어렵다.
강화학습
MDP는 무엇일까요?
MDP ( Markov Decision Process ) = 마르코프 결정 과정
- 강화학습은 주로 MDP(마르코프 결정 과정) 라는 모델 확률로 표현된다.
-
- 마르코프 가정 : 연속적인 시간에 따라 상태가 이어질 때, 어떠한 시점 t 의 상태는 바로 이전 시점 t-1의 상태에만 영향을 받는다는 가정이다.

- 마르코프 과정 : 마르코프 가정을 만족하는 연속적인 일련의 상태
- 마르코프 의사 결정 과정 : 5가지 집합으로 구성되어 있다.
S (상태state) , A (행동action) , P (상태전이확률state transition probability) , R (보상reward) , r (할인인자discount factor)
S (상태state) : 모든 MDP에서 가질 수 있는 모든 상태의 집합 {s1, s2, s3 ... , s | S | }
: x_t = s,s ∈ S (시점 t일때 상태 x는 상태집합 S 안에 있다.)
A (행동action) : 의사 결정자가 취할 수 있는 모든 행동의 집합
: 상태 s에서 취할 수 있는 행동 집합 A_s 로 표현한다.
P (상태전이확률state transition probability) :

시점 t 의 어떠한 상태 s_t 에서 행동 a를 취했을 때 s' 이 될 확률 P
R (보상reward) : R_a ( s,s' ) = 상태 s에서 행동 a로 인해 s'으로 전이되었을 때, 행동에 대한 보상(기댓값) 을 내린다.
r (할인인자discount factor) : 현재 얻게 되는 보상이 미래에 얻게 될 보상보다 얼마나 더 중요한지 나타내는 값 [ 0, 1 ] 사이의 값
: 할인 인자가 0.9 일때 , < 1, 0.9, 0.81, 0.729, 0.6561 > 이 된다. 먼 과거에 대한 보상일 수록 깎인다.
Markov reward process의 예시
위, 오른쪽, 아래, 왼쪽으로 움직이면서 출발점(S1)에서 목적지(S9)까지 함정(S7,S9)을 피하면서 도착하는 것을 목표

- 상태 전이 확률 P 에 따라서 행동을 결정한다.
- 함정에 빠지면 -0.1 보상, 목적지에 도착하면 0.1 보상을 주며 '상태 전이 확률'을 조정한다.

출발점 S1에서 a2, a2를 통해 함정 S3 에 빠질 때 , -0.1을 보상으로 준다.
s2에서 s3으로 이동한 것이 가장 최근 행동이기 때문에 보상을 그대로 준다.
그 전의 행동인 s1에서 s2로 이동한 것은 할인인자를 곱하여 보상을 반영한다.
할인요인을 곱해주며 보상을 반영하고, 상태 전이 확률을 조정해준다. 최종적으로 계속해서 경험을 쌓은 상태 전이 확률이 함정을 피하면서 목적지에 도착할 수 있도록 만들어 준다.
Q. 사용한 엔진(텐서 플로우 등)의 동향 및 프로젝트 진행시 엔진 진행방향
Q. 크로스 엔트로피가 뭔지? 왜 쓰는지?
Q. PCA 부분 설명
Q. 정규화 (L1,L2 규제)
Q. Drop out / 미니배치 이용 했을 때 과정, 과대적합일때 어떤 해결책이 있는지
출처 :blog.naver.com/kkang9901/222029504981
ko.wikipedia.org/wiki/%EB%A7%88%EB%A5%B4%EC%BD%94%ED%94%84_%EA%B2%B0%EC%A0%95_%EA%B3%BC%EC%A0%95
mole-starseeker.tistory.com/30