
모두야
CH7) RNN을 사용한 문장 생성 - (2) 본문
seq2seq
시계열 데이터 : 언어,음성,동영상
시계열↔시계열 데이터 변환 : 기계 번역→음성 인식
Encoder-Decoder 모델이다.


Encoder : 마지막 은닉상태 h에 입력 문장(출발어)를 번역하는 데 필요한 정보가 인코딩된다.
: LSTM의 은닉 상태 h 는 고정 길이 벡터이다.
Decoder : LSTM 계층이 벡터 h를 입력 받는다.

seq2seq는 LSTM 2개가 은닉 상태를 통해 이어져있다.

seq2seq 구현하기

단어 단위가 아닌, 문자 단위의 패턴을 학습한다.
57+5 가 입력 되면,
['5','7','+','5']라는 리스트로 처리된다.
(주의) 문자 수가 다 다르다.
= 샘플마다 데이터의 시간 방향 크기가 다르다.
= 가변 길이 시계열 데이터를 다룬다.
==> 미니배치 처리를 하기 위해서는, 미니배치에 속한 샘플들의 데이터 형상이 모두 같아야한다.
[패딩padding]

가변 길이 시계열 데이터를 미니배치로 학습하기 위한 방법
: 기존 데이터에 의미 없는 데이터를 채워 모든 데이터의 길이를 균일하게 맞추는 기법이다.
=> 존재하지 않던 패딩용 문자까지 seq2seq가 처리하게 된다.
==> seq2seq에 패딩 전용 처리를 추가한다.
- 패딩이 Decoder에 입력 되었다면, 손실의 결과에 반영되면 안된다.
: Softmax with Loss 계층에 '마스크' 기능을 추가하여 해결한다. - 패딩이 Encoder에 입력 되었다면, LSTM 계층이 이전 시각의 입력이 그대로 출력되어야 한다.
seq2seq 구현
- 2개의 RNN을 연결한 신경망이다.
1. Encoder 클래스


Embedding 계층 : 문자 ID를 문자 벡터로 변환한다.
LSTM 계층 : (오른쪽:시간 방향) - 은닉 상태와 셀을 출력한다.
(위쪽) - 은닉 상태 출력
마지막 문자를 처리한 LSTM 계층의 은닉 상태 h 는 Decoder로 전달된다.
2. Decoder 클래스


Encoder가 출력한 h를 받아 다른 문자열로 출력한다.
정답 데이터는 "_62"이지만
입력 데이터를 ['_','6','2',' ']로 주고, 출력은 ['6','2',' ',' ']가 되도록 학습시킨다.
문장 생성시 확률적 샘플링을 선택했지만, 덧셈 문제해결에서는 결정적 샘플링을 생성한다.

Softmax 계층을 사용하지 않고,
Affine 계층이 출력하는 점수가 가장 큰 문자 ID를 선택한다.
-> argmax(최댓값을 가진 원소 인덱스 선택)

seq2seq 개선
1. 입력 데이터 반전

- 학습 진행이 빨라진다.
- 최종 정확도도 좋아진다.
입력데이터 "나는 고양이로소이다" => 출력데이터 "I am a cat"
나 -> I까지 너무 멀다
입력데이터를 반전시켜주면
"이다, 로소, 고양이, 나는" => " I am a cat"
"나는"과 "I" 가 가까워져서 기울기가 더 잘 전달되고, 학습 효율이 좋다.
2. 엿보기(Peeky)
기존 Encoder에서 Decoder로 전달 될때 Encoder의 모든 정보를 가지는 h를 첫번째 LSTM 계층만 전달 받는다.
이렇게 중요한 정보를 가진 h를 Decoder의 모든 계층에 전달 해주며 공유한다. (concat 노드 활용)
=> LSTM 계층의 가중치와 Affine 계층의 가중치 형상이 바뀐다.
-> Encoder가 인코딩한 벡터도 입력되므로, 가중치 매개변수 형상이 그만큼 커진다.



seq2seq 사용 예시
- 기계 번역: 한 언어의 문장을 다른 언어의 문장으로 변환
- 자동 요약: 긴 문장을 짧게 요약된 문장으로 변환
- 질의응답: 질문을 응답으로 변환
- 메일 자동 응답: 받은 메일의 문장을 답변 글로 변환
1. 챗봇
상대방 말 -> 자신의 말 변환하여 대화한다.
2. 알고리즘 학습
파이썬 코드 수행
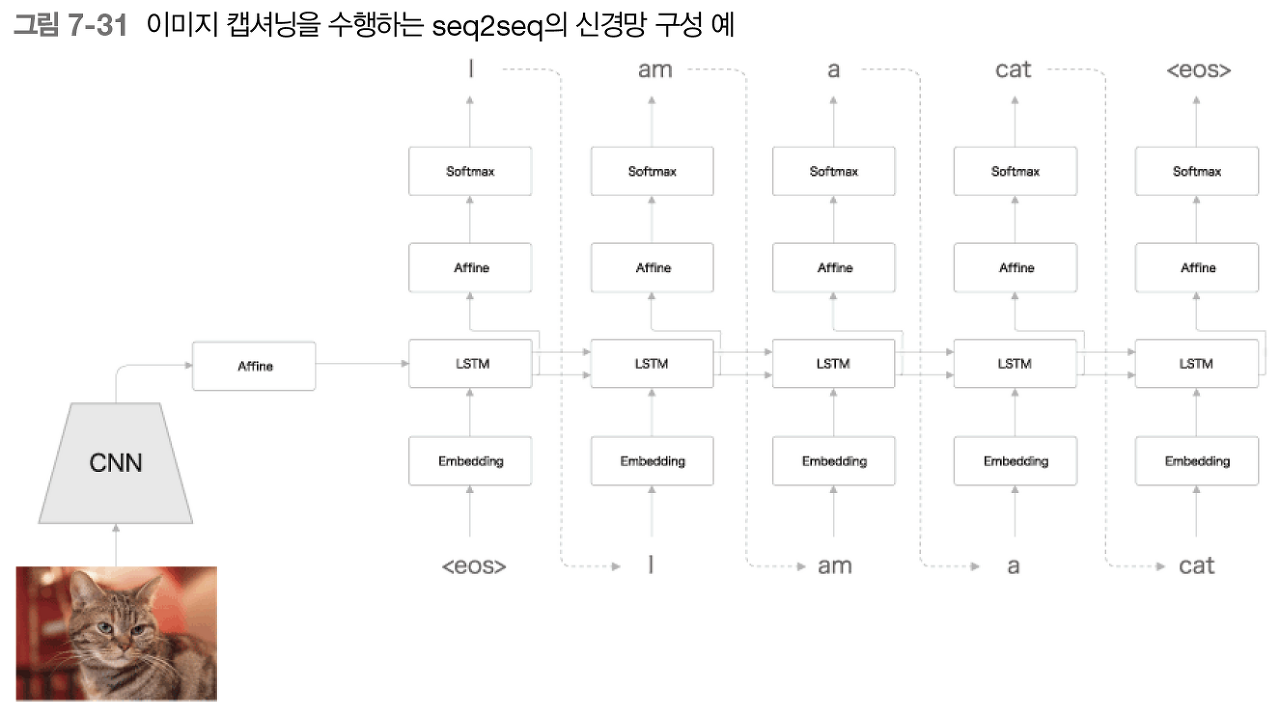
3. 이미지 캡셔닝
이미지를 문장으로 변환한다.
Encoder가 CNN으로 바뀌었다.
Decoder는 동일하다.
CNN의 출력은 특징맵(3차원)이다.
Decoder의 LSTM이 잘 처리할 수 있도록 1차원으로 평탄화(flatten)하여 Affine 계층으로 전달한다.
정리
- RNN을 이용한 언어 모델을 통해 문장을 생성하였다.
- seq2seq : Encoder와 Decoder를 연결한 모델로 RNN 2개를 조합한 구조이다.
- seq2seq 성능 향상을 위해 Reverse와 Peeky를 추가하였다.
- seq2seq를 더욱 개선할 수 있는 어텐션을 살펴볼 것이다.
'밑.시.딥 > 2권' 카테고리의 다른 글
| CH8) 어텐션 (0) | 2021.09.28 |
|---|---|
| CH7) RNN을 사용한 문장 생성 - (1) (0) | 2021.09.28 |
| CH6 ) 게이트가 추가된 RNN - (3) (0) | 2021.09.27 |
| CH6) 게이트가 추가된 RNN (기울기 문제점 대책) (0) | 2021.09.26 |
| CH6) 게이트가 추가된 RNN(기울기 폭발/ 기울기 손실) (0) | 2021.09.26 |



