
모두야
CH5) 순환 신경망(RNN) -(1) 본문
지금까지 살펴본 신경망을 피드포워드(feed forward) 신경망이다.
피드포워드 신경망이란, 흐름이 단방향 신경망이다.
-> 시계열 데이터 성질(패턴)을 충분히 학습할 수 없다.
==> 따라서, 순환 신경망 (RNN)이 등장한다.
word2vec 복습

- CBOW 모델 : 주변 단어(맥락)으로부터 정답(타깃)을 추측한다.
윈도우 크기는 하이퍼파라미터이다. 항상 좌우 대칭이였지만, 이번에는 맥락을 왼쪽 윈도우만으로 한정한다.


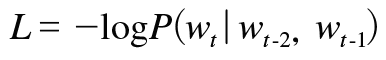
CBOW 모델의 학습 : 손실 함수(말뭉치 전체의 손실함수 총합)을 최소화하는 가중치 매개변수를 찾자.
-> 이러한 가중치 매개변수를 찾게 되면 CBOW 모델은 맥락으로부터 타깃을 더 정확히 추측할 수 있다.
==> 이러한 학습을 통해, 단어의 의미가 인코딩된 '단어의 분산 표현'을 얻을 수 있다.
맥락으로부터 추측된 타깃을 추측하는 것은 대체 어디에 이용되는가? 언어 모델에 사용된다!!
언어 모델 (Language Model)
: 단어 나열에 확률을 부여한다.
: 특정한 단어의 시퀸스에 대해서, 그 시퀸스가 일어날 가능성이 어느 정도인지(얼마나 자연스러운 단어 순서인지)를 확률로 평가한다.
ex) 'you say goodbye' 라는 단어 시퀸스에는 높은 확률(0.092)이지만,
'you say good die'라는 단어 시퀸스에는 낮은 확률(0.0000000032)를 출력하는 것이 언어모델이다.
- 기계 번역
- 음석 인식


동시확률 P는 사후확률로 나누어 총곱으로 나타낼 수 있다.
= 사후 확률의 총곱
사후 확률 : 타깃 단어보다 왼쪽에 있는 모든 단어를 맥락(조건)으로 했을 때의 확률이다.
- 맥락의 크기가 특정 값으로 정해져 있는 CBOW 모델을 언어 모델에 적용하게 되면, 정해진 맥락보다 더 왼쪽에 있는 단어의 정보는 무시된다.
Tom was watching TV in the room. Mary came into the room. Mary said hi to ?.
위의 예시에서 ?를 구하려고 할 때, 맥락의 크기가 10으로 한정되어 있다면 18번째인 Tom이라는 단어 정보는 얻지 못하여 제대로 답하기 어렵다.
이러한 문제를 해결하기 위해 무조건적으로 맥락의 크기를 키울 수는 없다.
- 또한, CBOW 모델에서는 맥락 안에서 단어의 순서가 무시된다.

- CBOW 모델은 입력층에서의 출력의 합이 은닉층으로 전달된다.
- (you,say)와 (say,you)를 똑같이 취급한다.
이를 해결하기 위해 단어의 합 대신, 단어들끼리 연결을 시키게 되면 해결할 수 있다. 하지만, 맥락의 크기에 비해 가중치 매개변수도 그만큼 늘어난다.
==> 순환 신경망 RNN : 맥락이 아무리 길더라도 맥락의 정보를 기억한다.
RNN (Recurent Neural Network : 순환 신경망)

닫힌 경로 = 순환 하는 경로 => 데이터가 순환하면서 정보가 끊임없이 갱신된다.
= 과거의 정보를 기억하는 동시에 최신 데이터로 갱신 된다.
t : 시각
시계열 데이터 입력 (x0,x1,x2, .... , xt) : 벡터
입력에 대응하는 출력 (h0,h1, .... , ht)

현재의 출력(ht)는 한 시각 이전 출력(ht-1)에 기초해 계산되었다.
RNN의 출력 ht : 은닉 상태(은닉 상태 벡터)
BPTT(Backpropagation Through Time) : 시간 방향으로 펼친 신경망의 오차역전파법

문제점
긴 시계열 데이터를 학습할 수록 시계열 데이터의 시간 크기가 커진다. BPTT가 소비하는 컴퓨팅 시간도 길어지면서 역전파 시 기울기가 불안정해진다. RNN 계층의 중간 데이터 메모리를 유지하여야 하기 때문이다.
Truncated BPTT : 잘라낸 작은 신경망에서의 오차역전파법
- 순전파 연결은 그대로 전달하고
- 역전파의 연결을 적당한 길이로 잘라내, 잘라낸 신경망 단위로 학습을 수행한다.
ex)
길이가 1,000개인 시계열 데이터 = 단어가 1,000개짜리 말뭉치 = 여러 문장을 연결한 것
신경망이 길수록 기울기 값이 점점 작아지다가 결국 소멸할 수도 있다.(미분하니까 : vanishing gradient 문제)

RNN 계층을 10개 단위로 역전파의 연결을 끊었다.
미래의 데이터에 대해 생각할 필요 없이 각각의 블록 단위로 독립적으로 오차역전파법을 수행한다.
(순전파의 연결은 끊어지지 않는다.)

Truncated BPTT
- 데이터를 순서대로 제공하기
- 미니배치별로 데이터를 제공하는 시작 위치를 옮기기
'밑.시.딥 > 2권' 카테고리의 다른 글
| CH6) 게이트가 추가된 RNN(기울기 폭발/ 기울기 손실) (0) | 2021.09.26 |
|---|---|
| CH5) 순환 신경망(RNN) -(2) (0) | 2021.09.24 |
| CH4) word2vec 속도 개선 (0) | 2021.09.20 |
| CH3) word2vec - (2) (0) | 2021.09.20 |
| CH3) word2vec - 간단ver (1) (0) | 2021.09.19 |



